
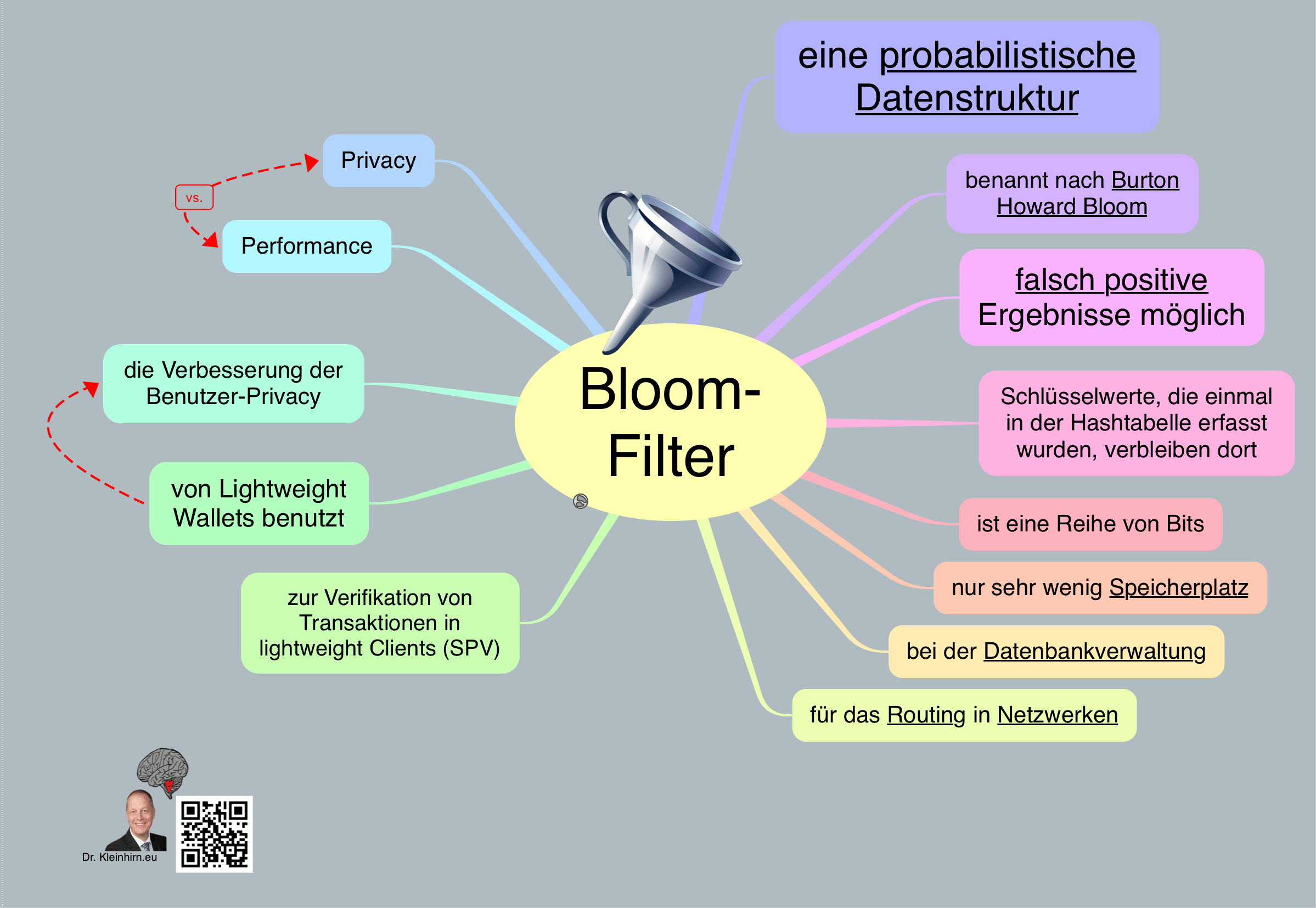
Was sind Bloom- Filter und wozu werden sie gebraucht?
Ein Bloom-Filter ist eine Datenstruktur, die in der Informatik häufig zum schnellen Testen der Mitgliedschaft von Elementen in einer Menge verwendet wird. Es wurde 1970 von Burton Howard Bloom vorgeschlagen. Ein Bloom-Filter ist eine kompakte Speicherstruktur, die eine Liste von binären Bits verwendet, um die Mitgliedschaft von Elementen in einer Menge darzustellen. Es ist sehr platzsparend und ermöglicht es, schnell zu überprüfen, ob ein Element in einer Menge enthalten ist oder nicht. Bloom-Filter finden in vielen Anwendungen Verwendung, darunter Netzwerkprotokolle, Datenbanken, Internet-Suchmaschinen, Routing-Tabellen, Wallets und vieles mehr.
Ein Bloom-Filter besteht aus einer Tabelle von m Bits und einer Reihe von k Hashfunktionen, die Elemente aus einer Menge in eine der m Positionen in der Tabelle abbilden. Wenn ein Element in den Bloom-Filter eingefügt wird, wird es durch jede der k Hashfunktionen geleitet und in k verschiedene Bits der Tabelle eingefügt. Wenn ein Element abgefragt wird, wird es ebenfalls durch jede der k Hashfunktionen geleitet und die k Bits in der Tabelle überprüft. Wenn alle k Bits gesetzt sind, ist das Element möglicherweise in der Menge enthalten. Wenn jedoch auch nur ein Bit nicht gesetzt ist, ist das Element definitiv nicht in der Menge enthalten.
Ein Bloom-Filter ist sehr effizient bei der Verwendung von Speicherplatz, da es keine Daten zu den Elementen selbst speichert. Es verwendet nur die Informationen der Hashfunktionen, um die Mitgliedschaft eines Elements in einer Menge zu bestimmen. Wenn jedoch eine Hashfunktion dieselbe Position in der Tabelle für zwei verschiedene Elemente zurückgibt, wird das Bloom-Filter falsch positive Ergebnisse liefern, was bedeutet, dass es fälschlicherweise angibt, dass ein Element in der Menge enthalten ist, wenn es nicht der Fall ist. Ein weiteres Problem ist, dass das Bloom-Filter keine Möglichkeit hat, Elemente zu entfernen, die einmal hinzugefügt wurden. Dies bedeutet, dass es eine Wahrscheinlichkeit gibt, dass ein Element fälschlicherweise als in der Menge enthalten angezeigt wird, obwohl es nicht mehr vorhanden ist.
Die Leistung eines Bloom-Filters hängt von der Größe der Tabelle und der Anzahl der Hashfunktionen ab. Wenn die Tabelle zu klein ist oder zu wenige Hashfunktionen verwendet werden, steigt die Wahrscheinlichkeit falsch positiver Ergebnisse. Wenn jedoch die Tabelle zu groß ist oder zu viele Hashfunktionen verwendet werden, steigt der Speicherbedarf und die Leistung wird beeinträchtigt.
Ein Bloom-Filter wird normalerweise verwendet, wenn die Kosten für einen falsch positiven Test niedrig sind und die Kosten für einen falsch negativen Test hoch sind. Ein Beispiel ist die Überprüfung von E-Mail-Adressen, um Spam zu identifizieren oder in einem Bitcoin-Wallet um die privacy zu schützen. Ein Bloom-Filter kann verwendet werden, um zu bestimmen, ob eine E-Mail-Adresse möglicherweise Spam ist. Wenn das Bloom-Filter eine E-Mail-Adresse als Spam kennzeichnet, wird sie möglicherweise in eine Quarantäne-Liste verschoben und von einem Administrator manuell überprüft. Wenn das Bloom-Filter eine E-Mail-Adresse jedoch als sicher markiert, wird sie weitergeleitet und in der Regel nicht weiter überprüft. In diesem Fall ist ein falsch positives Ergebnis akzeptabel, da es keine direkten negativen Auswirkungen hat. Ein falsch negatives Ergebnis hingegen kann schwerwiegende Folgen haben, da es bedeutet, dass eine schädliche E-Mail nicht erkannt und blockiert wird.
Es gibt verschiedene Variationen des Bloom-Filters, die auf verschiedene Anwendungsfälle zugeschnitten sind. Ein Beispiel ist der Counting Bloom-Filter, der es ermöglicht, Elemente hinzuzufügen und zu entfernen und auch die Häufigkeit der Elemente in der Menge zu verfolgen. Ein anderer Typ ist der Cuckoo-Filter, der weniger Speicherplatz benötigt als ein Bloom-Filter, aber auch effizienter bei der Entfernung von Elementen ist.
Zusammenfassend ist ein Bloom-Filter eine effiziente Datenstruktur zur schnellen Überprüfung der Mitgliedschaft von Elementen in einer Menge. Es verwendet eine Liste von binären Bits und Hashfunktionen, um zu bestimmen, ob ein Element möglicherweise in der Menge enthalten ist. Obwohl es eine hohe Leistung und einen geringen Speicherbedarf hat, ist es anfällig für falsch positive Ergebnisse und hat keine Möglichkeit, Elemente zu entfernen. Bloom-Filter finden in vielen Anwendungen Verwendung, insbesondere wenn die Kosten für einen falsch positiven Test niedrig sind und die Kosten für einen falsch negativen Test hoch sind.